
A 2x2-es mátrix a következőképpen néz ki:
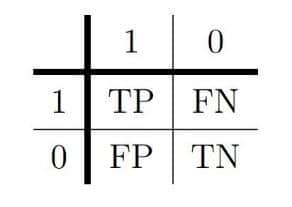 1. Tévesztésmátrix bináris esetben
A ’True-False’, és a ’Positive-Negative’ angol szavak variációiból kapjuk a négyféle kategóriát. Értelemszerűen a ’True’ kezdetűek jelentik a helyesen osztályozott pontok számát, és bármilyen megtévesztő ebben az esetben, de a Positive jelenti azt, hogy az illető nem fizeti vissza a hitelt. A tévesztési mátrix alapján könnyen számítható az osztályozó modellünk pontossága:
1. Tévesztésmátrix bináris esetben
A ’True-False’, és a ’Positive-Negative’ angol szavak variációiból kapjuk a négyféle kategóriát. Értelemszerűen a ’True’ kezdetűek jelentik a helyesen osztályozott pontok számát, és bármilyen megtévesztő ebben az esetben, de a Positive jelenti azt, hogy az illető nem fizeti vissza a hitelt. A tévesztési mátrix alapján könnyen számítható az osztályozó modellünk pontossága:
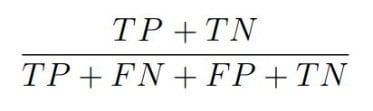 2. Pontosság
Ez az összes helyesen beosztályozott megfigyelések aránya. A fent említett problémánál ez azt jelenti, hogy 100 emberből 85-nél eltalálta az algoritmus, hogy vissza fogja-e fizetni a kölcsönt. Ami viszont nem derül ebből ki, hogy abból a maradék 15-ből mennyi olyan van, aki valójában nem fogja visszafizetni. Érthető okokból, a hitelintézeteket ez az eset érdekli jobban, ezért ebben az esetben, érdemes két másik teljesítménymutatót mérvadónak venni: a precizitást (precision), és a felidézést (recall).
2. Pontosság
Ez az összes helyesen beosztályozott megfigyelések aránya. A fent említett problémánál ez azt jelenti, hogy 100 emberből 85-nél eltalálta az algoritmus, hogy vissza fogja-e fizetni a kölcsönt. Ami viszont nem derül ebből ki, hogy abból a maradék 15-ből mennyi olyan van, aki valójában nem fogja visszafizetni. Érthető okokból, a hitelintézeteket ez az eset érdekli jobban, ezért ebben az esetben, érdemes két másik teljesítménymutatót mérvadónak venni: a precizitást (precision), és a felidézést (recall).
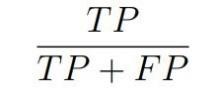 3. Precizitás
3. Precizitás
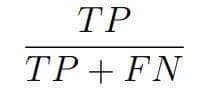 4. Felidézés
Látható, hogy ezek beszédesebb mutatók ebben az esetben, hiszen a precizitás megadja a helyesen “nem fizetőnek” osztályozottak arányát az összes “nem fizetőnek” osztályozott között, míg a felidézés az összes ténylegesen “nem fizető” között. Mindig érdemes figyelembe venni az üzleti igényeket, amikor kiválasztjuk a validáló metrikánkat.
Egy másik fontos szempont az adat összetétele. Maradjunk ugyanennél a példánál. A tanító adathalmazból tudjuk, hogy 100-ból 7 ügyfél nem fizeti vissza a hitelt, a többi 93 igen. Egy ilyen részlehajló adathalmaznál félrevezető lehet a pontosságot venni. Vegyünk egy véletlen osztályozót, ami mindentől függetlenül kiosztja valahogy a címkéket a megfelelő arányban. Könnyű kiszámolni, hogy ez a véletlen osztályozó is ~87%-os pontosságú. Ennek fényében a 85%-os AdaBoost már nagyon gyengének számít.
Természetesen ezek a gondolatok nem csak az osztályozásra érvényesek. Regressziónál, klaszterezésnél, és idősoros előrejelzésnél is érdemes mindig figyelembe venni az üzleti igényeket és az adat tulajdonságait, amikor megválasztjuk a modell teljesítményét mérő metrikát.
Dobsa Dániel - Data Scientist - Nextent Informatika Zrt.
4. Felidézés
Látható, hogy ezek beszédesebb mutatók ebben az esetben, hiszen a precizitás megadja a helyesen “nem fizetőnek” osztályozottak arányát az összes “nem fizetőnek” osztályozott között, míg a felidézés az összes ténylegesen “nem fizető” között. Mindig érdemes figyelembe venni az üzleti igényeket, amikor kiválasztjuk a validáló metrikánkat.
Egy másik fontos szempont az adat összetétele. Maradjunk ugyanennél a példánál. A tanító adathalmazból tudjuk, hogy 100-ból 7 ügyfél nem fizeti vissza a hitelt, a többi 93 igen. Egy ilyen részlehajló adathalmaznál félrevezető lehet a pontosságot venni. Vegyünk egy véletlen osztályozót, ami mindentől függetlenül kiosztja valahogy a címkéket a megfelelő arányban. Könnyű kiszámolni, hogy ez a véletlen osztályozó is ~87%-os pontosságú. Ennek fényében a 85%-os AdaBoost már nagyon gyengének számít.
Természetesen ezek a gondolatok nem csak az osztályozásra érvényesek. Regressziónál, klaszterezésnél, és idősoros előrejelzésnél is érdemes mindig figyelembe venni az üzleti igényeket és az adat tulajdonságait, amikor megválasztjuk a modell teljesítményét mérő metrikát.
Dobsa Dániel - Data Scientist - Nextent Informatika Zrt.


