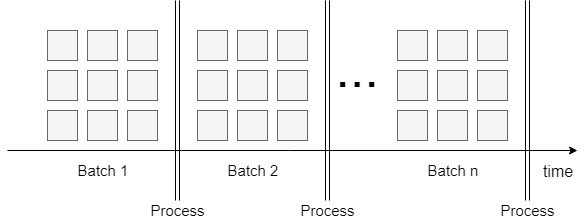
Batch feldolgozás
Az első és talán a legismertebb technika a batch feldolgozás. Egy batch azon adatok halmaza, amelyeket egy adott időszak során összegyűjtöttek és csoportosítottak. A batch időtartama változhat, hónapoktól kezdve, heteken, napokon, órákon vagy akár sűrűbb feldolgozási időn át, amint később látni fogjuk. Az időszak hossza általában meghatározza a feldolgozandó adatok mennyiségét. Hosszabb időn keresztül könnyen több millió sor generálódhat, ezért sok időre vagy nagy számítási erőforrásra van szükségünk minden adat feldolgozásához. Azonban a batch feldolgozást bármilyen időszakra ütemezhetjük és így a teljesítményproblémák kezelhetők. Nagy hátrány azonban, hogy a batch feldolgozás késleltetése és erőforrásigénye jóval nagyobb, mint a stream feldolgozásnak.
A batch feldolgozásra jó példa egy aggregálási feladat, ahol a nap folyamán generált kis adathalmazokat szeretnénk összesíteni.
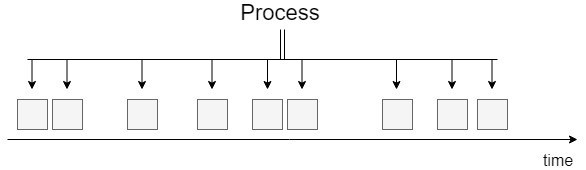
Stream feldolgozás
A stream feldolgozás folyamatos adatfolyamként működik, ami rögtön kezeli az adatokat, amint azok megérkeznek. A fő különbség a batch feldolgozáshoz képest az, hogy nincs késedelem: a rekordokat különálló darabokként dolgozzák fel, nem pedig batch-ként. Az adatfolyamnak van néhány különleges tulajdonsága a batch feldolgozáshoz képest, amelyet figyelembe kell venni egy stream job megvalósítása során. Az egyik az, hogy nem tudjuk kontrollálni az adatbeviteli sebességet. A másik, hogy az adatrekordok folyamatosan érkeznek, többnyire bármiféle sorrendiség vagy ellenőrzés nélkül. Azonban az olyan megoldások, mint például az Apache Kafka igénylik a sorrendiség kezelését és a pontos szemantikát. Továbbá a stream feldolgozásra jellemző, hogy ha egy elem megérkezett, azt azonnal kezelnünk kell: fel kell dolgozni, el kell dobni vagy tárolni kell.
Egy példa stream feldolgozási job-ra, amikor valós időben szeretnénk feldolgozni és kiértékelni egy gyártó robot szenzorainak adatait.
Microbatch feldolgozás
Van egy harmadik megoldás is, amely ötvözi az első kettőt: a mikro-batch feldolgozás.
Ezt a technikát többnyire stream feldolgozás alá kell besorolni, mivel közel valósidejű eredményt tud nyújtani, de eredetileg batch alapelveken alapszik. Bemenetként adatfolyammal is rendelkezik, de az azonnali feldolgozás helyett egy adott ideig (általában néhány másodpercre vagy percre) várakozik az adatok gyűjtésére (mikro-batch) és végrehajtja a műveletet ezeken a kötegelt adatokon.
Egy példa a mikro-batch job-ra, amikor komplex logikát alkalmazunk a gyártórobot bejövő szenzor adataira.
Eszközök
Batch feldolgozás
Az Apache Hadoop egy nyílt forráskódú Big Data eszköz, amelynek célja a clusteren tárolt adatok feldolgozása. A batch feldolgozás szempontjából a szoftvernek két fő összetevője van, mégpedig a MapReduce és a HDFS. A MapReduce egy programozási modell, amely lehetővé teszi hatalmas mennyiségű adat elosztott és hibatűrő módon történő feldolgozását. A HDFS egy elosztott és hibatűrő tárolóréteg a Hadoop-ban, amelyet általános, hétköznapi hardverekre terveztek.
Microbatch
Az Apache Spark eredeti célja hasonló a Hadoop-hoz, szintén működik batch-eken, de nagyon kis méretben (micro-batch). A Spark központi eleme a rugalmas elosztott adatkészlet (Resilient Distributed Dataset, RDD). Ez a bejövő adatok hibatűrő tárolására szolgál. Az eszköz számos adatforrással integrálható, például az Apache Kafka-val: a Spark az adatokat a forrásból tételekre osztja és feldolgozza. Noha a Hadoop és a Spark is batch-ekkel működnek, van közöttük egy kulcsfontosságú különbség: a utóbbinak százszor gyorsabb a memóriája a Hadoopnál. Számos implementáción keresztül sikerült elérni ezt a jelentős teljesítményt, egy saját egyéni DAG ütemező, egy lekérdezés optimalizáló és egy fizikai végrehajtási motor használatával.
Streaming
Noha az Apache Spark segítségével felépíthetünk egy közel valósidejű rendszert, valamint - elméletileg - elérhetünk 1 ms mikro-batch méretet is, működése miatt nem tekinthető hatékony megoldásnak. A Spark a rekordokat összegyűjti egy pufferben, majd egy job-ban dolgozza fel. Azonban minden job-ot be kell ütemezni és végre kell hajtani (például minden 1 ms-ban), ami az átviteli sebesség jelentős csökkenését okozhatja. A 2.3-as verziótól kezdve a Spark támogatja az új, még kísérletinek tekinthető alacsony késleltetésű feldolgozási módot, amelyet folyamatos feldolgozásnak (Continuous Processing) hívnak.
Amennyiben nem akarunk kísérleti megoldást használni, akkor fontolóra kell vennünk az Apache Flink-et. Az Apache Flink egy keretrendszer és elosztott feldolgozási motor az állapotalapú számításokhoz. A közel valósidejű adatfolyam-feldolgozás elérése érdekében az Flink korlátlan adatfolyamokat (adatrekordok áramlása) és transzformációkat használ. Amikor egy Flink program végrehajtásra kerül, a motor leképezi azt streaming adatfolyamokba.
Az adatfolyamok tetszőlegesen irányított aciklusos grafikonokra (DAG) hasonlítanak. Az Flink támogatja a batch feldolgozást is, így ebben az esetben van egy korlátozott adatfolyamunk.
|
Batch |
Stream |
| A bemeneti sebesség vezérlése |
igen |
nem |
| Adatok mérete |
korlátos |
korlátlan |
| Sorrendiség kontrollja |
igen |
nem |
| Késleltetés |
magas |
pár mp (<1s) vagy kevesebb (<100ms) |
| Eszközök |
Hadoop |
Spark (micro-batch), Flink (stream) |
Mint látható, a batch feldolgozással egyszerre nagy, de korlátozott mennyiségű adatot kezelhetünk, és komplex logikát használhatunk, míg az stream feldolgozással alacsony késleltetés érhető el, amely egy valósidejű alkalmazásban szükséges.
Ne felejtsd el, hogy az
IThon.info-n több cégről és képzésről is találsz információt! Kövess minket a
Facebook,
Linkedin és
Instagram oldalunkon is, hogy ne maradj le semmiről!



